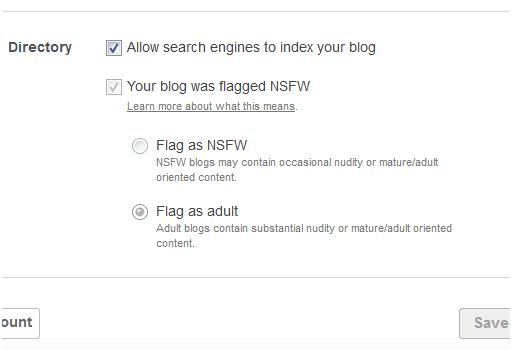
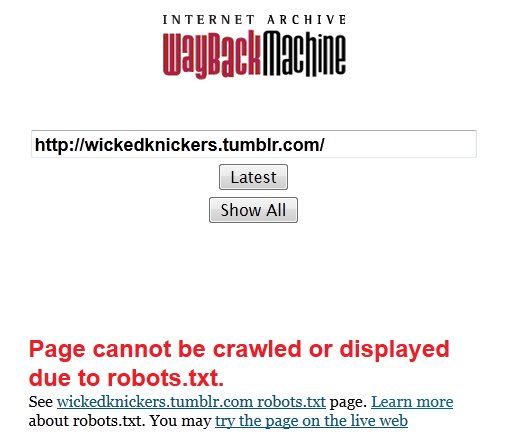
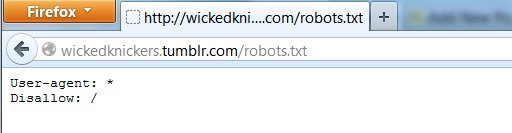
How To Back Up Your Adult Tumblr Blog
Monday, May 20th, 2013 -- by Bacchus
As promised in my last post, this is the post in which I tell you how to make a full and complete backup of your porn Tumblr blog (or, really, any Tumblr). My goal for you is a set of files on your own hard drive that contains all the text and all the links and all the pictures (even the full-sized high-res click through ones) that you’ve got on your current Tumblr blog, all linked together in a way that you can open the site in your browser and browse through it just like you would online. This can be done. It’s not even very hard. And once you’ve got it done, you’ll have all the raw material you would need re-create your tumblr blog on some other hosting, if anything should happen to Tumblr or to your porn blog on Tumblr.
But why should you worry about that? Why might you need a Tumblr backup?
Well, as I write this, the news is official: Yahoo has purchased Tumblr for more than a billion dollars, cash. (Tumblr shareholders did not want any stinky Yahoo stock, which should tell you something.) The business press has been pointing out for awhile that Yahoo will need to deal with what the suits in the corporate/financial/advertising world consider to be Tumblr’s “porn problem“. And Yahoo itself has a terrible reputation for buying cool, trendy, successful websites, running them into the ground or neglecting them to death, and then shuttering them. (Remember Geocities? Shaddup, it was cool once. A long time ago…) As Violet Blue puts it in her Sex Tech column at ZDNet:
Yahoo! is well-known for misunderstanding the user base of properties it acquires and ruining – then scrapping – once-active and beloved properties.
…
But if Flickr’s rep [under Yahoo’s ownership] with poorly policing ‘art nudes’ is any hint of Tumblr’s fate, then we’re likely to see lots of once-happy users forced into confusing self-rating protocols, having their accounts banned and years of content deleted with no recourse, and a new content policy practically written by trolls who want the easiest path to shut down people they don’t like.
I, myself, have been speculating for a couple of weeks that Tumblr would soon start cracking down on its “porn problem”, starting with an idle prediction in my The Pornocalypse Comes For Us All post and expanding on it when I discovered (apparently before pretty much anybody else noticed) that Tumblr had started trying to hide all the porn blogs from Google. At first the specific reason was not clear, but in the last few days the drumbeat of anticipatory news about the Yahoo purchase began to make the pieces fall into place. It’s safe to speculate that Tumblr began trying to minimize its “porn problem” while the sale was being negotiated, and there’s a strong basis for concern that (swiftly or eventually) Yahoo will continue that process and attempt to rid the Tumblr ecosystem of porn blogs. Even if they don’t, their track record of failure with acquisitions is such that there’s a good chance that all of Tumblr will have failed or shut down within a few years. And, for people who aren’t following Bacchus’s First Law of The Internet, backups are really important.
Enough nattering. You want tools and instructions.
I’m going to show you two ways to do this, a best-but-somewhat-complex way and an easy-but-somewhat-incomplete way.
Complete Tumblr Backup Solution:
First, the good way, the one recommended by my friend and prolific Tumblr-user Dr. Faustus. I’ve tested this and it works. When you’re done, you’ll have a complete copy of your Tumblr site on your own hard drive that you could navigate with your internet unplugged.
The program you want is: HTTrack/WinHTTrack Website Copier. It’s an open-source free-software general utility for copying and mirroring websites, available for most current versions of Windows as well as for a wide variety of Linux/Unix flavors. The Windows version presents a fairly old-fashioned interface with a bunch of cryptic options, but most of them come pre-set with sensible defaults that you actually don’t need to mess with. Plus, there’s good documentation. (Note well: there are many other programs out there that can accomplish this job. I’m recommending this one because it works and because I’m aware of it; I’m not claiming it’s the best or the easiest.)
Download the software and install it, then run it. You’ll be presented with a welcome screen where you need to click “Next”. Then, this screen:
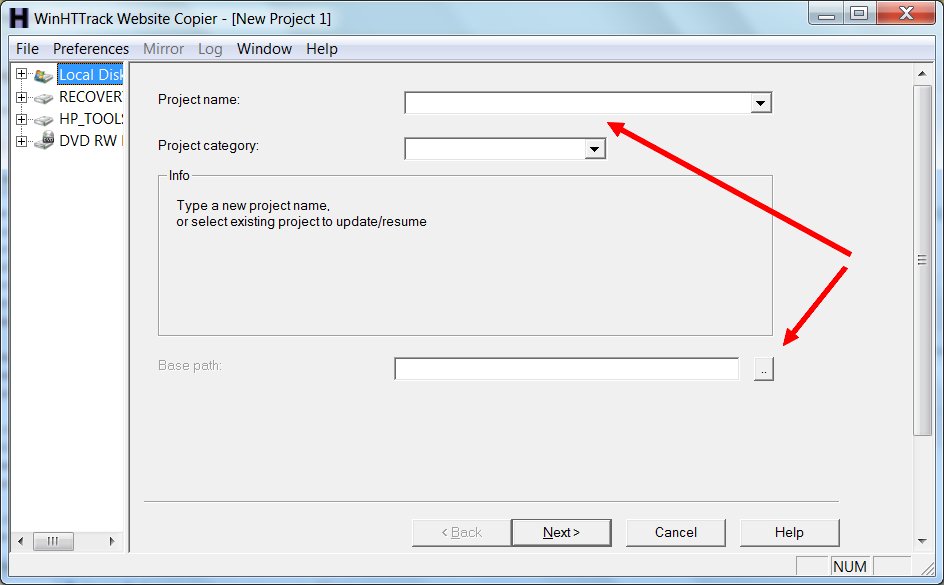
The arrows show you the two fields that need your attention. All you really need to do is give this backup project a name and tell the software where to save the backup. Then hit “Next”:
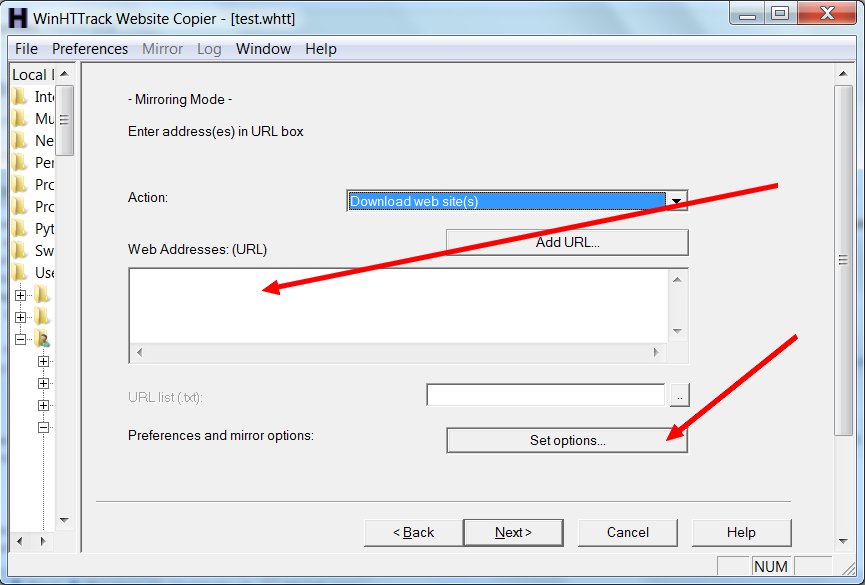
On this screen you need to type in the URL for the Tumblr you want to back up. It will be something like: http://yourtumblr.tumblr.com — and there’s one vital reason you need to press the “Set options” button. When you do, you’ll see this:
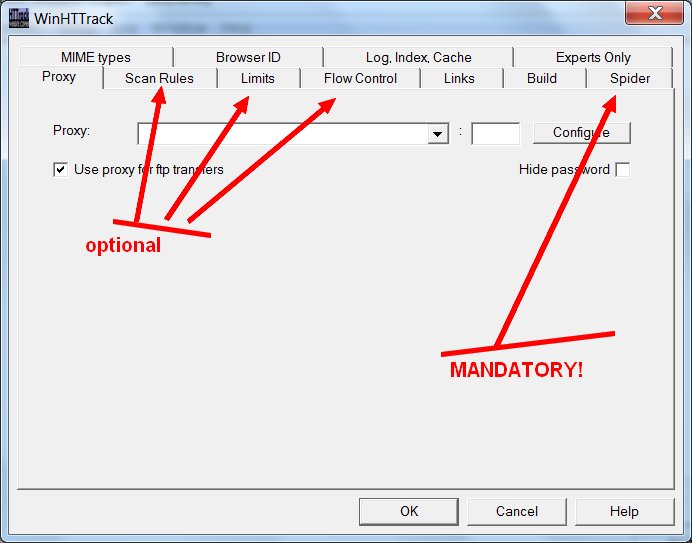
I’ve pointed arrows at three optional settings tabs that you may want to adjust, and at the one mandatory options tab where you must change a setting. I’m going to ignore the optional ones for now, except to say that you would tinker with these if you wanted to change the sorts of media files you’re saving beyond the basic .gif, .jpg, and .png (you’d need to do this if you were saving a Tumblr that had .wav files or .zip files or .mp3s), or if you need to limit this program from slamming your internet connection too hard. It’s the mandatory “Spider” tab you really need to click:
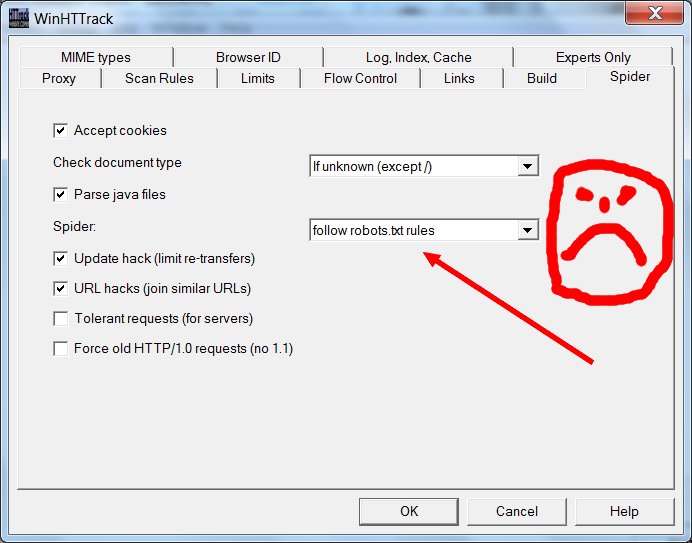
See the box where it says “follow robots.txt rules”? That robots.txt they’re talking about is the very same unwelcome bugger that got us into this mess in the first place. As a general proposition, one should usually instruct one’s electronic robot spider minions to follow robots.txt rules; unruly robot spiders are a menace to the internet and to web servers everywhere. But this principle of polite internet behavior assumes that you haven’t had your own data locked behind the hostile barbed wire of some corporate data-silo forced-labor camp where the robots.txt has been put in place to hide your porny visage so that the corporate camp commissars will look prettier in the pages of Forbes Magazine and the Wall Street Journal. When it’s your data, you’re perfectly within your moral rights to ignore the robots.txt in order to extricate it; and so that’s what we’re going to do here. Change it using the drop-down menu to say “no robots.txt rules”.
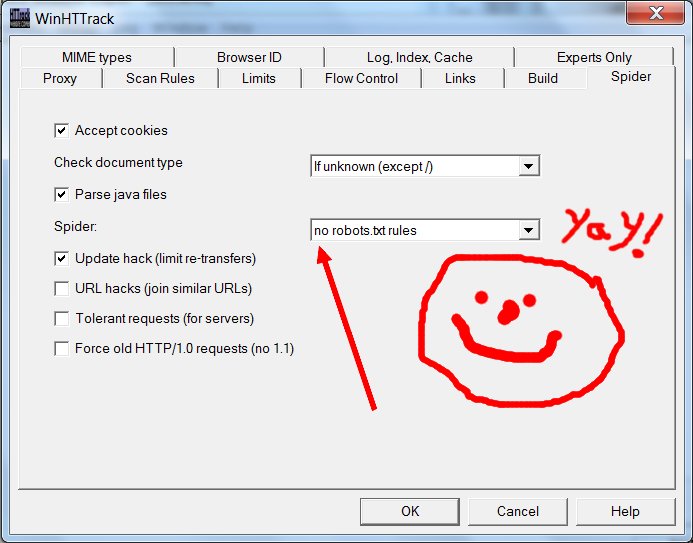
Yay! We’re almost done. Hit the “OK” button, hit “Next”, hit “Finish”, and your site copying should begin.
How long it will take to finish depends on the available bandwidth of your net connection, the memory and processing speed of your computer, and on whether you tweaked any of the options that control things like how many simultaneous connections your computer is making and how many files it’s trying to download in parallel. It also depends on how many pages there are on the Tumblr blog you are backing up, and on how big the images are. The default settings seem to be fairly gentle about not maxing out your internet connection or putting an unruly amount of strain on the server at the site you are trying to copy. Using default settings and a fairly crappy internet connection, I downloaded a test adult Tumblr blog (with permission of the blogger) in about two hours, that had roughly a thousand posts and took up about three-quarters of a gigabyte of room on my hard drive. Your mileage may, and probably will, vary.
What does success look like? You’ll have a folder on your hard drive with the name you provided on the first options screen. If you open it, you will find many sub-folders, and much that may seem mysterious. You should also find a file called “index.html” — and if you click on it, it should open in a new browser window where you’ll be looking at your backed up Tumblr site, using nothing but the files on your hard drive.
What have we not accomplished? Well, you’ve made what should be a full and true copy, but it’s not a nice clean export in some standard format that you could use to easily import all your posts into another content management system or blogging tool. HTML files and related images are scattered through a system of directories and subdirectories that, while logical, may not be the simplest thing to work with. Using the data you’ve got, a clever computer person could generate an XHTML document (or something similar) that could be semi-automatically imported into (say) WordPress. But it would take parsing; it would take work. Figuring out how to take the copy you just made and turn it back into a non-Tumblr website is a solvable problem, but how easy or hard it might be to actually do it depends on your access to computer expertise and tools. For now, you’re safe in the knowledge that you’ve got all the posts you’ve made this past however-many years. You’ve got the images, you’ve got their metadata (any tags you set for them and any credits you may have reblogged or included) and you’ve got the clever things you said about them, all, safe on your hard drive.
Now would be a good time to back up your hard drive. I’m just sayin’.
Partial/Easier Tumblr Backup Solution:
Perhaps all the above is too involved or too complex for you. Or maybe you tried, and failed. For you, there’s a simple little web tool called Backup Jammy where you just type your desired URL into the box and press “Go”. That’s it. A single huge web page appears on your screen with all your Tumblr post content in a simplified format. Then you can use your browser’s “Save as web page” function to save it to your hard disk.
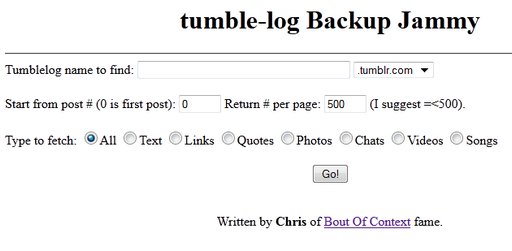
I don’t really recommend this tool. It doesn’t save nearly as much data as HTTrack/WinHTTrack does. In particular, all you seem to get is the standardized Tumblr 500-pixel versions of your images, and none of the higher-res versions that you may have posted. And if you have more posts than will fit in the memory of your computer at one time, you will have to do this in chunks, and save the chunks with appropriate names so you don’t overwrite one with another. It’s a less-complete solution. However, it’s also much easier, especially if your Tumblr blog only has a couple of hundred posts. And it might be enough for you. Certainly it’s better than nothing.
Conclusion
Given the existential threat that the adult Tumblr ecosystem is facing, I hope that smarter people than me will soon take some of the many fine website copying/mirroring tools that are out there, and meld them with friendly idiot-resistant interfaces and powerful parsing tools in a way that provides a seamless Tumblr export in a standardized format that’s ready for import into other blogging tools and posting on other social media platforms. I very much hope so, anyway. But that won’t happen today. A crufty backup you make today is worth a thousand times more than a perfect backup you never make before the platform goes down or is nerfed into uselessness or puts up filters to prevent the users from spidering their own content.
I’m painfully aware that the adult Tumblr backup solutions I’m offering here are messy, imperfect, and incomplete. All I can say in my defense is that they are the very best that I could find and test and describe and put up on the web in a single working day. For many of you, the Tumblr backup options listed here won’t be satisfactory or sufficient, and I apologize in advance for that. But if even a few of the great porn Tumblrs that went dark to public searching in the last few weeks are saved now and preserved on a hard drive and someday returned to the public web because of today’s effort, I’ll count it a day very well spent.
Similar Sex Blogging: