|
|

The Sex Blog Of Record
Friday, February 27th, 2015 -- by Bacchus
Now that Google is spinning down the porn raid sirens and walking their shit back from last week’s announced intention to forbid “sexually explicit or graphic nude images or video”, it’s worth paying some careful attention the language used today by Jessica Pelegio, the social product support manager at Google. From her title, this sounds like the woman who is the boss of the people who will be enforcing the policy, so her understanding of the policy is likely to be supremely relevant. And in her announcement, she writes:
“We’ve decided to step up enforcement around our existing policy prohibiting commercial porn.”
The emphasis is mine. “Our existing policy prohibiting commercial porn.” What, what? Does Blogger even have an “existing policy prohibiting commercial porn”? Quick, let’s go look, and snap a screenshot before it changes:
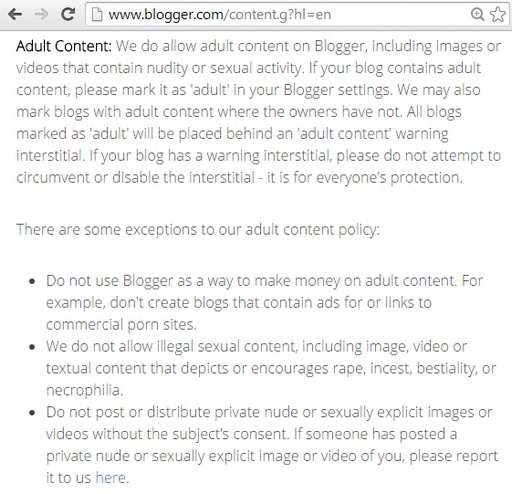
The key sentences for our purposes are:
Do not use Blogger as a way to make money on adult content. For example, don’t create blogs that contain ads for or links to commercial porn sites.
Strictly speaking, this is not a “policy prohibiting commercial porn.” One of the biggest categories of adult blogs on Blogger/Blogspot used to be a (what we would now consider to be Tumblr-style) constant flow of commercial porn, posted without links and purely for the amusement of the poster. You could squint and interpret the URL watermarks on commercial porn photos as “ads for…commercial porn sites”, but Google never did this (that we know of). The existing/current policy simply doesn’t prohibit commercial porn, though it might be said to prohibit porn posted with commercial intent. Does Jessica Pelegio think about the policy with that much nuance? Her phrasing today suggests: not so much.
But while we are parsing words, let’s fire up the Wayback Machine and have a look at how this “existing policy prohibiting commercial porn” has been phrased and characterized by Google since June of 2013 when Google dreamed it up.
Stepping back through time, we discover that between October 23, 2014 and November 6, 2014, they added one clarifying word: “ads or links to commercial porn sites” became “ads for or links to commercial porn sites.” Ads (in general) became ads (for commercial porn sites) so this narrowed the scope of Google’s prohibiting examples. Trivial, but cool. (At the same time as this wording change, Blogger added the current stern language prohibiting attempts to circumvent the interstitial adult warning.)
That takes us back (without any other changes I can discover) to the infamous June 30, 2013, when the current policy was implemented. (Here it is in the Wayback Machine on July 5th, 2013, so you an see for yourself.) Here’s the big announcement from then:
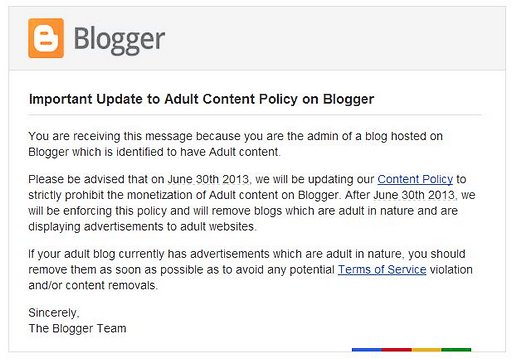
What Pelegio now calls a “policy prohibiting commercial porn” was then described as a new policy prohibiting blogs “which are … displaying advertisements to adult websites” or “currently has advertisements which are adult in nature.” That seems quite a bit narrower than the “policy prohibiting commercial porn” Pelegio now considers it to be.
For completeness, let’s compare the language before June 30, 2013 to the current policy. “Do not use Blogger as a way to make money on adult content” has not changed; that was been the policy since the earliest appearance of the policy page in the Wayback Machine on January 7, 2012. But before June 30, the prohibited example was “For example, don’t create blogs where a significant percentage of the content is ads or links to commercial porn sites.” The big policy change in June 2013 was going zero-tolerance on the ads and links to commercial porn sites — no more insignificant percentages allowed.
So, just to be clear: up until today, Google has always allowed commercial porn on Blogger/Blogspot, as long as that porn was not posted “as a way to make money on adult content.” Noncommercial use of commercial porn was fine, and before June of 2013, so too were de minimis links to commercial porn sites.
If the social product support manager is planning to “step up enforcement around our existing policy prohibiting commercial porn” when there currently is no such policy, for safety you should assume that either the policy will be changing or that the enforcement will hew to the manager’s view of what it means even when that’s not what it actually says. Neither is good news for the future of adult blogs on Blogger/Blogspot.
Sure, let’s all heave a sigh of relief that the March 23rd deadline is no longer looming. But don’t get complacent. If you’ve still got adult content on any Google property, get it out while you still can. Verbum sapienti satis.
Similar Sex Blogging:
Thursday, February 26th, 2015 -- by Bacchus
Subtitle: How To Tweak Your Robots.txt File So That The Wayback Machine Will Show The World What Google Refuses to Display
One of the reasons the adult internet will take such a hard body blow when Google makes sexually explicit Blogger (Blogspot) blogs forcibly private on March 23 is that in a single moment they will break millions of links around the web. As Violet Blue puts it:
When Google forces its “unacceptable” Blogger blogs to go dark, it will break more of the Internet than you think. Countless links that have been accessible on Blogger since its inception in 1999 will be broken across the Internet.
What’s your reflex response when you follow a link and find it broken? If it’s like me, you immediately click the link on your bookmarks toolbar that takes you to the WayBack Machine at the Internet Archive: https://archive.org/web/
The Wayback Machine and the Internet Archive’s crawling robot are powerful tools. Like all powerful tools, exactly how they work is sometimes obscure. Here are the basics: The IA crawler bot crawls the web, visiting as many pages as it can manage. And it stuffs those pages into the huge databases of the Wayback Machine, where the pages are preserved for all time, or anyway for as long as the Internet Archive can manage).
Preservation, however, is not the same as sharing and display. Some of the pages the Wayback Machine has in its databases are not displayed to the public. The reasons for this are covered in a complex FAQ, but for our purposes it’s enough to understand that sometimes when the IA crawler bot encounters a robots.txt file on a domain, that robots.txt file in effect tells the bot to go pound sand while pissing up a rope. And when the bot finds such a robots exclusion request, the bot politely backs away from the crazy person and (supposedly) refrains from capturing the current version of the pages. (See also: ROBOTS.TXT IS A SUICIDE NOTE)
In such a case (for reasons) the Wayback Machine will stop displaying any of the pages “protected” by the robot exclusion request. Any user requests will get this ugly red error instead:
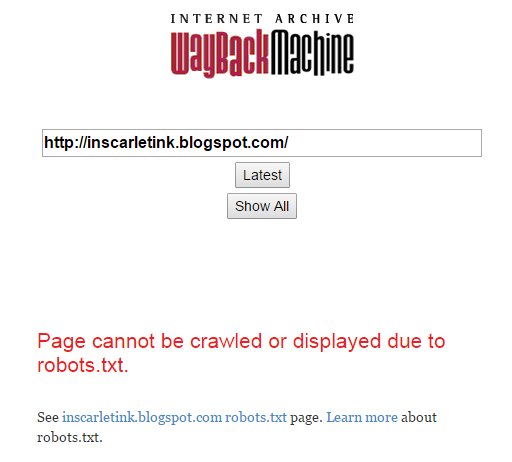
That’s so even if the IA bot has been to these pages a hundred times and has years of history in successive snapshots of the pages. If the robots.txt exclusion is present, the Wayback Machine refuses to display any of that old crawl data.
But note carefully what that explanation (and the Archive.org FAQ) does not say. The Wayback Machine does not display those old pages it still has in its database — but it certainly does not delete them from its database, either.
The Internet Archive and The WayBack Machine are not in the business of deleting shit. I take it as an article of faith that they for damned-skippy-sure never delete anything just because of a few lines in a robots.txt file.
Nothing on a website is there forever. That includes obnoxious robots.txt files. And when the robots.txt files go away, suddenly those old crawled pages become visible again. I actually saw this happen after Tumblr reversed itself in 2013 and at least temporarily stopped forcing a hostile robots.txt file onto its adult bloggers. The hostile robots.txt files stopped being so hostile, so the Wayback Machine could once again display the old pages that it had crawled and displayed upon request prior to Tumblr imposing the robots.txt files.
Consider now an adult Blogger (blogspot.com) blog that’s already private, because the owner chose to make it that way. Here’s the robots.txt file that Blogger displays by default:
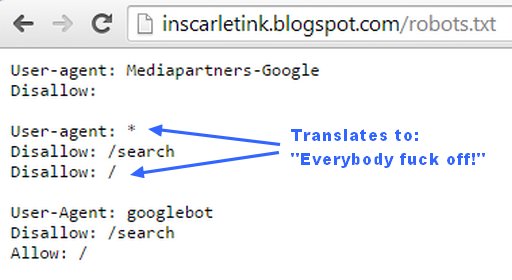
There’s a good chance (if only because Google hasn’t telegraphed any planned changes to the functionality of its private Blogger blogs) that this same exclusionary robots.txt will appear for every sexually explicit Blogger blog that is forcibly flagged “private” on March 23.
So, if you have a sexually explicit Blogger blog right now, there’s a good chance it’s in the Wayback Machine already, in whole or in part. (You can check: go here and paste your URL in the box.)
Now let’s fast forward to March 24th. Suppose I notice some old ErosBlog post that links to your Blogger sex blog. I click the link and it’s now broken, because Google has forcibly set your blog to “private”. If I ask the Wayback Machine to show me the old page for the broken link, I’ll get the ugly red error. But the Internet Archive still has that old page in its database. And someday, when things change, the Wayback Machine could theoretically serve the old page once again. (Google might change its policy. The Internet Archive might change its policy. Google might have gone bankrupt, or sold the Blogspot.com domain to America Online. The Internet might have changed beyond all recognition. The horse might even learn to sing, we can’t know.)
From a practical standpoint, this fact that the old pages of your blog are still in the databases of the Internet Archives — but barred from public display — doesn’t help us much. But if you feel that your sexually explicit blog is a legitimate part of the cultural history of the early 21st century, it matters rather a lot. Because your blog is not lost to history — it’s just lost to those of us who are interested in it right now.
(Yes, I am assuming that the Internet Archives will be successful in preserving and transmitting its data — our data — into the deep future. That’s by no means assured. If you have oodles of spare money kicking around, giving them some of your oodles would no doubt help assure it.)
Thus this post is, in part, a “don’t panic” message about all the sex blogs that are about to disappear from the internet. I called it a “hard body blow” at the top of this post, and it is. But it’s not a fatal blow. Yes, it will break a ton of our links and create a big dark hole in our adult internet. But it won’t, if the gods keep smiling on Brewster Kahle and his people, disappear those old blogs forever.
But I wouldn’t be well over a dozen paragraphs into this huge wall of text if all I had to say was “don’t panic.” Here’s an interesting thing that I just discovered about a blog on Blogger: Google currently allows blog owners to set the contents of their own custom robots.txt files, even on blogs flagged as private.
You can log into your adult Blogger blog right now and set a custom robots.txt file. If you want the Internet Archive to keep displaying archived pages once Google breaks all your inbound links, set it like this under Settings – Search Preferences – Crawlers and Indexing:
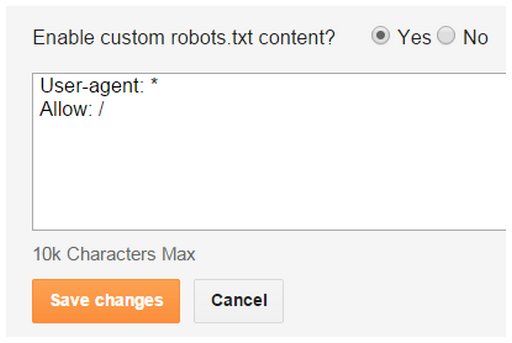
It can’t hurt anything, and it might mean that all your broken links can be “repaired” by people who encounter them. They will just paste the broken link into the Wayback Machine and be served a copy of the page as it used to be before Google went insane.
Will it work? Well, we don’t know for sure. Google could easily impose a uniform and restrictive robots.txt file on its adult bloggers after it forces them into “private” mode, by ignoring the custom setting or by removing it from the Blogger interface altogether. But — by design or oversight — Google might not do that, either.
If this trick does work, it means there will more traces remaining available to the public of your years of explicit sex blogging. And people who are bitterly disappointed by broken links to your stuff will have at least one useful thing to try.
Hopefully you’ll be taking more direct action too, like migrating your blog to private hosting. But if you can’t spare the resources to do that, this custom robots.txt change is a little thing you can do that may help a little.
P.S. If you have some technical skill and want to take a more proactive approach to saving our erotic cultural history, Archiveteam (these are the folks who saved Geocities, who also want you to understand they are not the Internet Archive) seems to have taken the news about Google’s erotic blog freakout as a sign that Blogger in general is no longer to be trusted. Because they have now announced they are “downloading everything”. This is great news, but it’s a project of epic size, and they can always use more help.
Similar Sex Blogging:
Monday, July 1st, 2013 -- by Bacchus
Well, today’s the big day — the day that Google has announced it will start deleting adult Blogger (blogspot.com) blogs that have any “monetization of adult content” on them. Since there’s no telling how Google defines “adult” or “monetization” and no way to predict how aggressively they will pursue this campaign, only time will tell how broad and deep the casualties will be.
Hence this post. I’m hoping to use the comments here for people to aggregate information on our losses in the sex blogging community. If you’ve lost an adult blog to Google’s deletion campaign (your own or a favorite browsing destination) please post the name, defunct link, and a few words of description in the comments.
Thanks!
Similar Sex Blogging:
Wednesday, June 26th, 2013 -- by Bacchus
My twitter feed just lit up with outrage about the email Google just sent to some or all of the adult bloggers on Blogger/BlogSpot blogs (of which there are a lot):
Important Update to Adult Content Policy on Blogger
You are receiving this message because you are the admin of a blog hosted on Blogger which is identified to have Adult content.
Please be advised that on June 30th 2013, we will be updating our Content Policy to strictly prohibit the monetization of Adult content on Blogger. After June 30th 2013, we will be enforcing this policy and will remove blogs which are adult in nature and are displaying advertisements to adult websites.
If your adult blog currently has advertisements which are adult in nature, you should remove them as soon as possible as to avoid any potential Terms of Service violation and/or content removals.
Sincerely,
The Blogger Team
Great thanks to Molly for sending me a copy; I myself do not have any Blogger-hosted sites because of Bacchus’s First Rule. However, Blogger/BlogSpot have a long history as the most reliable and long-lived host for free blogging, and (other than a heavy hand with an adult warning page that went up a few years ago) they’ve always been entirely adult-friendly. I didn’t see this coming, not in any specific way.
Obviously currently active bloggers can (if they move quickly — four day’s warning, seriously Google?) delete offending affiliate links and save their blogs. But the real impact here will be in to the long list of moribund adult blogs going back for most of a decade. There are many thousands of these, and being moribund, there’s no hope that they’ll be saved. Not only will they vanish from the web (I wonder if Google will use robots.txt to kill them in the WayBack Machine like Tumblr does?) but when they go, they’ll take with them an “installed base” of ancient blogroll links the departure of which will be strongly felt by all of the adult sites they ever linked to. It’s going to be a Page Rank bloodbath, for the folks who care about SEO and all that.
The pornocalypse comes for us all, I tell ya.
Similar Sex Blogging:
Monday, May 20th, 2013 -- by Bacchus
As promised in my last post, this is the post in which I tell you how to make a full and complete backup of your porn Tumblr blog (or, really, any Tumblr). My goal for you is a set of files on your own hard drive that contains all the text and all the links and all the pictures (even the full-sized high-res click through ones) that you’ve got on your current Tumblr blog, all linked together in a way that you can open the site in your browser and browse through it just like you would online. This can be done. It’s not even very hard. And once you’ve got it done, you’ll have all the raw material you would need re-create your tumblr blog on some other hosting, if anything should happen to Tumblr or to your porn blog on Tumblr.
But why should you worry about that? Why might you need a Tumblr backup?
Well, as I write this, the news is official: Yahoo has purchased Tumblr for more than a billion dollars, cash. (Tumblr shareholders did not want any stinky Yahoo stock, which should tell you something.) The business press has been pointing out for awhile that Yahoo will need to deal with what the suits in the corporate/financial/advertising world consider to be Tumblr’s “porn problem“. And Yahoo itself has a terrible reputation for buying cool, trendy, successful websites, running them into the ground or neglecting them to death, and then shuttering them. (Remember Geocities? Shaddup, it was cool once. A long time ago…) As Violet Blue puts it in her Sex Tech column at ZDNet:
Yahoo! is well-known for misunderstanding the user base of properties it acquires and ruining – then scrapping – once-active and beloved properties.
…
But if Flickr’s rep [under Yahoo’s ownership] with poorly policing ‘art nudes’ is any hint of Tumblr’s fate, then we’re likely to see lots of once-happy users forced into confusing self-rating protocols, having their accounts banned and years of content deleted with no recourse, and a new content policy practically written by trolls who want the easiest path to shut down people they don’t like.
I, myself, have been speculating for a couple of weeks that Tumblr would soon start cracking down on its “porn problem”, starting with an idle prediction in my The Pornocalypse Comes For Us All post and expanding on it when I discovered (apparently before pretty much anybody else noticed) that Tumblr had started trying to hide all the porn blogs from Google. At first the specific reason was not clear, but in the last few days the drumbeat of anticipatory news about the Yahoo purchase began to make the pieces fall into place. It’s safe to speculate that Tumblr began trying to minimize its “porn problem” while the sale was being negotiated, and there’s a strong basis for concern that (swiftly or eventually) Yahoo will continue that process and attempt to rid the Tumblr ecosystem of porn blogs. Even if they don’t, their track record of failure with acquisitions is such that there’s a good chance that all of Tumblr will have failed or shut down within a few years. And, for people who aren’t following Bacchus’s First Law of The Internet, backups are really important.
Enough nattering. You want tools and instructions.
I’m going to show you two ways to do this, a best-but-somewhat-complex way and an easy-but-somewhat-incomplete way.
Complete Tumblr Backup Solution:
First, the good way, the one recommended by my friend and prolific Tumblr-user Dr. Faustus. I’ve tested this and it works. When you’re done, you’ll have a complete copy of your Tumblr site on your own hard drive that you could navigate with your internet unplugged.
The program you want is: HTTrack/WinHTTrack Website Copier. It’s an open-source free-software general utility for copying and mirroring websites, available for most current versions of Windows as well as for a wide variety of Linux/Unix flavors. The Windows version presents a fairly old-fashioned interface with a bunch of cryptic options, but most of them come pre-set with sensible defaults that you actually don’t need to mess with. Plus, there’s good documentation. (Note well: there are many other programs out there that can accomplish this job. I’m recommending this one because it works and because I’m aware of it; I’m not claiming it’s the best or the easiest.)
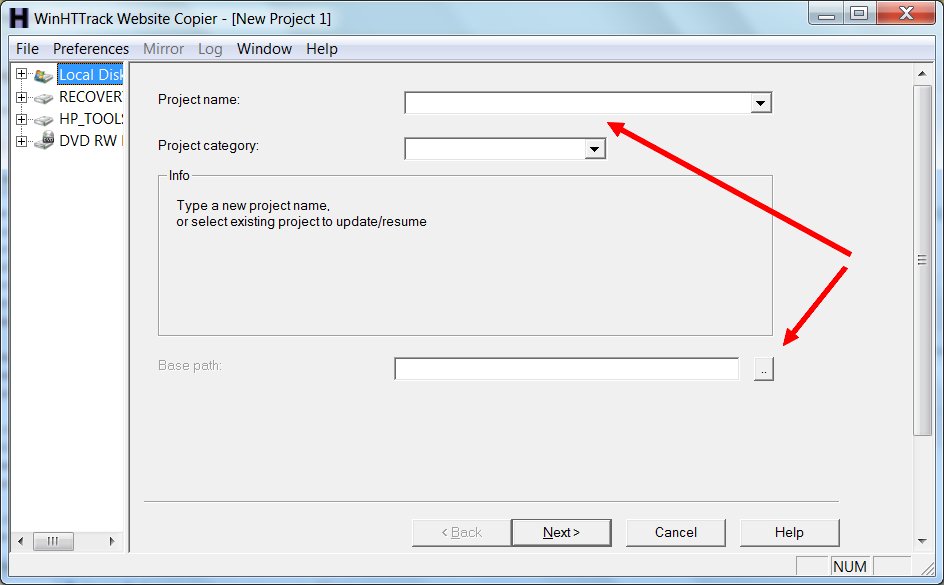
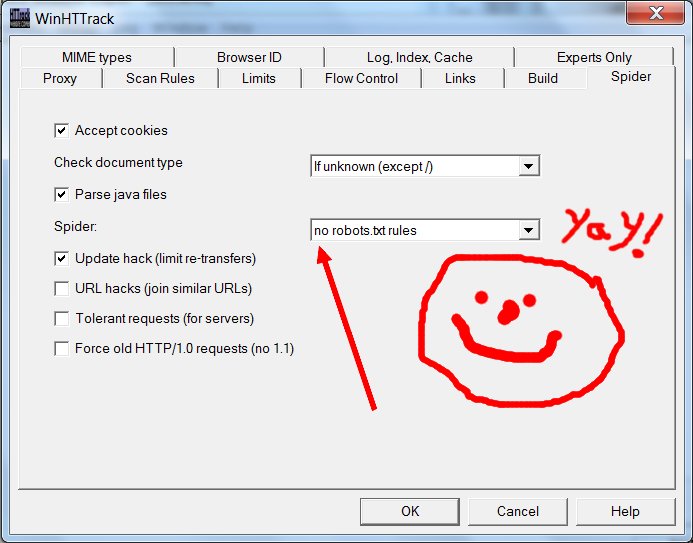
Download the software and install it, then run it. You’ll be presented with a welcome screen where you need to click “Next”. Then, this screen:
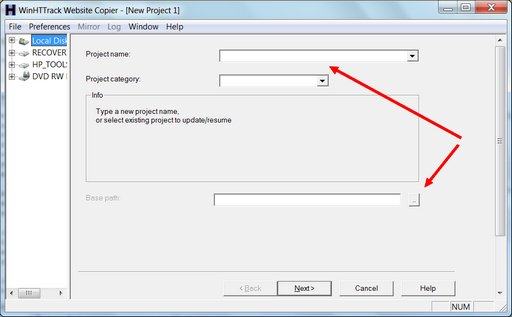
The arrows show you the two fields that need your attention. All you really need to do is give this backup project a name and tell the software where to save the backup. Then hit “Next”:
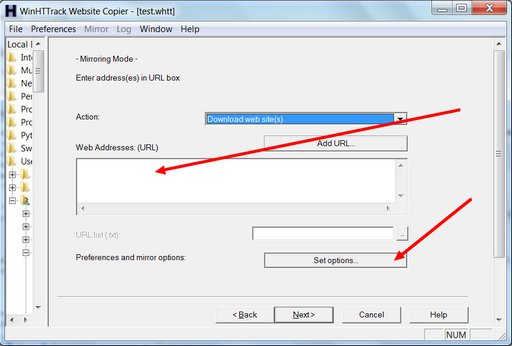
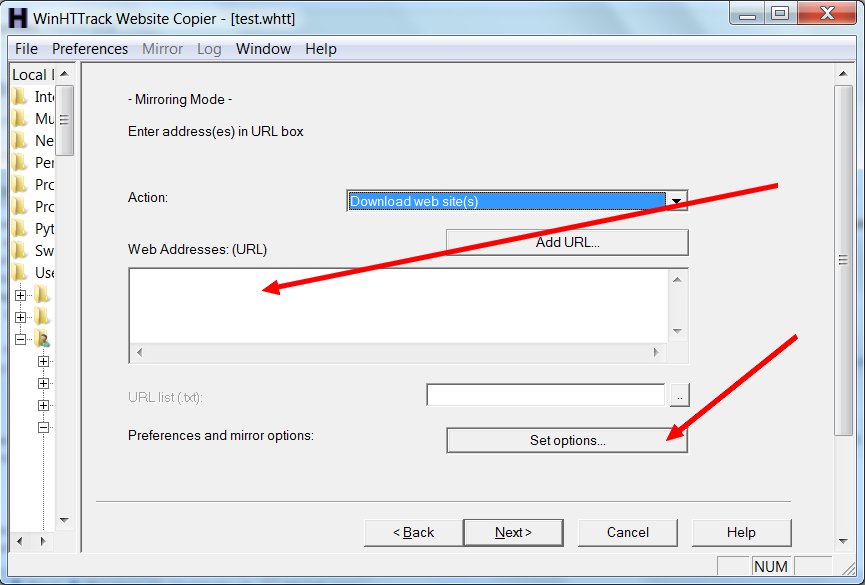
On this screen you need to type in the URL for the Tumblr you want to back up. It will be something like: http://yourtumblr.tumblr.com — and there’s one vital reason you need to press the “Set options” button. When you do, you’ll see this:
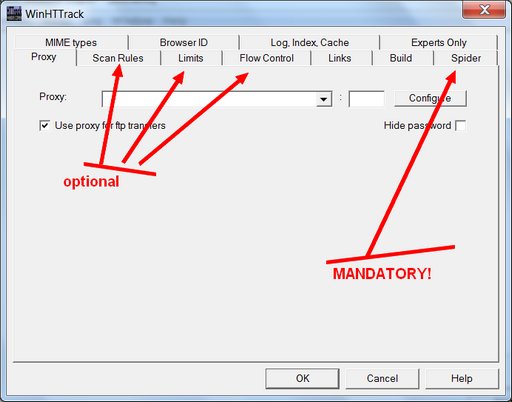
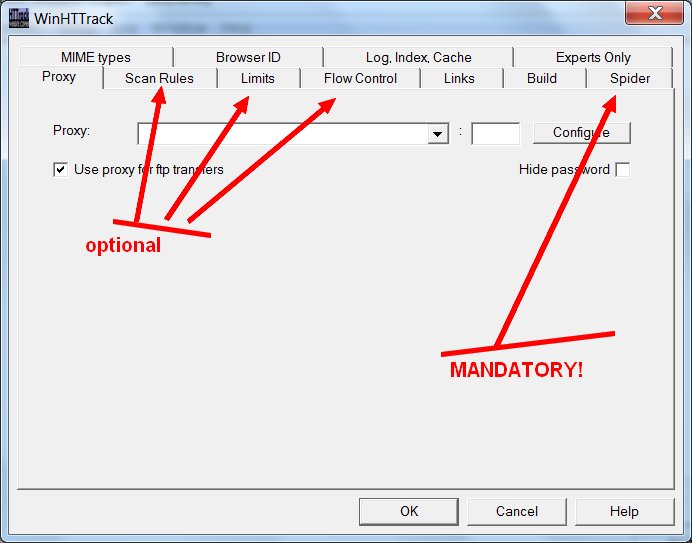
I’ve pointed arrows at three optional settings tabs that you may want to adjust, and at the one mandatory options tab where you must change a setting. I’m going to ignore the optional ones for now, except to say that you would tinker with these if you wanted to change the sorts of media files you’re saving beyond the basic .gif, .jpg, and .png (you’d need to do this if you were saving a Tumblr that had .wav files or .zip files or .mp3s), or if you need to limit this program from slamming your internet connection too hard. It’s the mandatory “Spider” tab you really need to click:
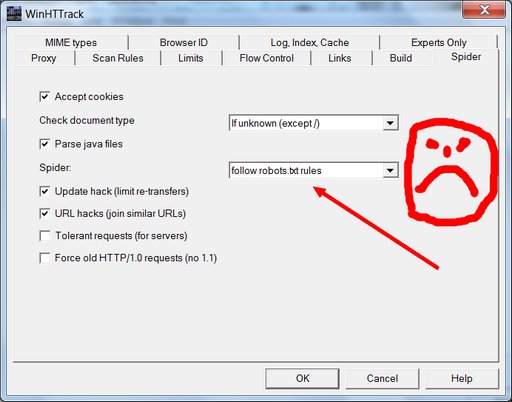
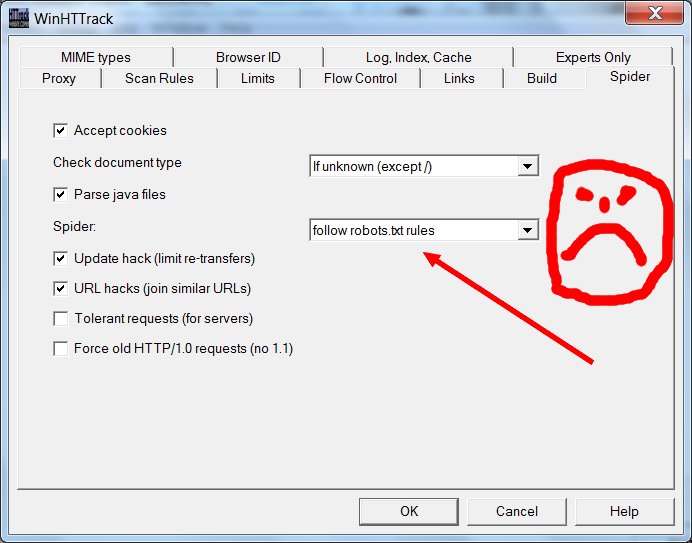
See the box where it says “follow robots.txt rules”? That robots.txt they’re talking about is the very same unwelcome bugger that got us into this mess in the first place. As a general proposition, one should usually instruct one’s electronic robot spider minions to follow robots.txt rules; unruly robot spiders are a menace to the internet and to web servers everywhere. But this principle of polite internet behavior assumes that you haven’t had your own data locked behind the hostile barbed wire of some corporate data-silo forced-labor camp where the robots.txt has been put in place to hide your porny visage so that the corporate camp commissars will look prettier in the pages of Forbes Magazine and the Wall Street Journal. When it’s your data, you’re perfectly within your moral rights to ignore the robots.txt in order to extricate it; and so that’s what we’re going to do here. Change it using the drop-down menu to say “no robots.txt rules”.
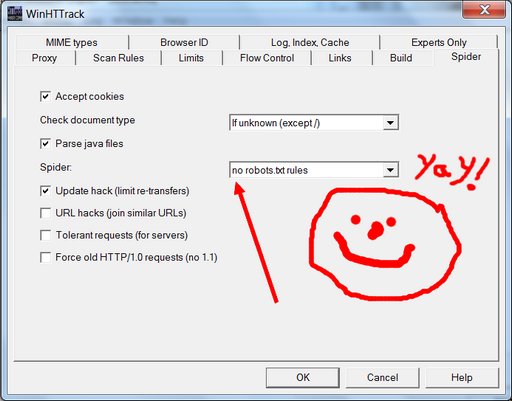
Yay! We’re almost done. Hit the “OK” button, hit “Next”, hit “Finish”, and your site copying should begin.
How long it will take to finish depends on the available bandwidth of your net connection, the memory and processing speed of your computer, and on whether you tweaked any of the options that control things like how many simultaneous connections your computer is making and how many files it’s trying to download in parallel. It also depends on how many pages there are on the Tumblr blog you are backing up, and on how big the images are. The default settings seem to be fairly gentle about not maxing out your internet connection or putting an unruly amount of strain on the server at the site you are trying to copy. Using default settings and a fairly crappy internet connection, I downloaded a test adult Tumblr blog (with permission of the blogger) in about two hours, that had roughly a thousand posts and took up about three-quarters of a gigabyte of room on my hard drive. Your mileage may, and probably will, vary.
What does success look like? You’ll have a folder on your hard drive with the name you provided on the first options screen. If you open it, you will find many sub-folders, and much that may seem mysterious. You should also find a file called “index.html” — and if you click on it, it should open in a new browser window where you’ll be looking at your backed up Tumblr site, using nothing but the files on your hard drive.
What have we not accomplished? Well, you’ve made what should be a full and true copy, but it’s not a nice clean export in some standard format that you could use to easily import all your posts into another content management system or blogging tool. HTML files and related images are scattered through a system of directories and subdirectories that, while logical, may not be the simplest thing to work with. Using the data you’ve got, a clever computer person could generate an XHTML document (or something similar) that could be semi-automatically imported into (say) WordPress. But it would take parsing; it would take work. Figuring out how to take the copy you just made and turn it back into a non-Tumblr website is a solvable problem, but how easy or hard it might be to actually do it depends on your access to computer expertise and tools. For now, you’re safe in the knowledge that you’ve got all the posts you’ve made this past however-many years. You’ve got the images, you’ve got their metadata (any tags you set for them and any credits you may have reblogged or included) and you’ve got the clever things you said about them, all, safe on your hard drive.
Now would be a good time to back up your hard drive. I’m just sayin’.
Partial/Easier Tumblr Backup Solution:
Perhaps all the above is too involved or too complex for you. Or maybe you tried, and failed. For you, there’s a simple little web tool called Backup Jammy where you just type your desired URL into the box and press “Go”. That’s it. A single huge web page appears on your screen with all your Tumblr post content in a simplified format. Then you can use your browser’s “Save as web page” function to save it to your hard disk.
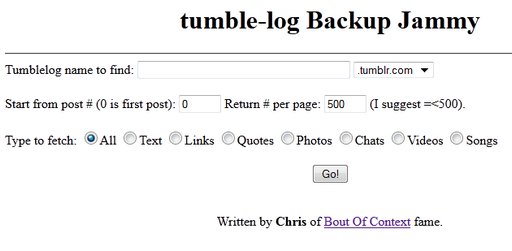
I don’t really recommend this tool. It doesn’t save nearly as much data as HTTrack/WinHTTrack does. In particular, all you seem to get is the standardized Tumblr 500-pixel versions of your images, and none of the higher-res versions that you may have posted. And if you have more posts than will fit in the memory of your computer at one time, you will have to do this in chunks, and save the chunks with appropriate names so you don’t overwrite one with another. It’s a less-complete solution. However, it’s also much easier, especially if your Tumblr blog only has a couple of hundred posts. And it might be enough for you. Certainly it’s better than nothing.
Conclusion
Given the existential threat that the adult Tumblr ecosystem is facing, I hope that smarter people than me will soon take some of the many fine website copying/mirroring tools that are out there, and meld them with friendly idiot-resistant interfaces and powerful parsing tools in a way that provides a seamless Tumblr export in a standardized format that’s ready for import into other blogging tools and posting on other social media platforms. I very much hope so, anyway. But that won’t happen today. A crufty backup you make today is worth a thousand times more than a perfect backup you never make before the platform goes down or is nerfed into uselessness or puts up filters to prevent the users from spidering their own content.
I’m painfully aware that the adult Tumblr backup solutions I’m offering here are messy, imperfect, and incomplete. All I can say in my defense is that they are the very best that I could find and test and describe and put up on the web in a single working day. For many of you, the Tumblr backup options listed here won’t be satisfactory or sufficient, and I apologize in advance for that. But if even a few of the great porn Tumblrs that went dark to public searching in the last few weeks are saved now and preserved on a hard drive and someday returned to the public web because of today’s effort, I’ll count it a day very well spent.
Similar Sex Blogging:
Wednesday, May 15th, 2013 -- by Bacchus
If you’ve got an adult blog on Tumblr, there’s a good chance Tumblr uses robots.txt to exclude the search engines from indexing it. Did you know that?
Two weeks ago in The Pornocalypse Comes For Us All, I wrote:
Who is next? My guess would be Tumblr. Tumblr is, of all the big platforms, perhaps the most porn friendly; there’s lots of porn on there and the Terms of Service do not prohibit it… But Tumblr is, famously, a popular platform in search of a revenue-generating business model. And we’ve learned that the suits have no loyalty to the porn users who made their platform popular. So, my bold prediction is that as Tumblr casts about for a business model, one of their steps will be to “clean this place up”…
And now, guess what? I’ve discovered that Tumblr uses robots.txt to bar all search engine access to blogs flagged as adult. If you’ve got an adult Tumblr, go look at your own settings. Do you see that first checkbox, the one that says “allow search engines to index your blog”?
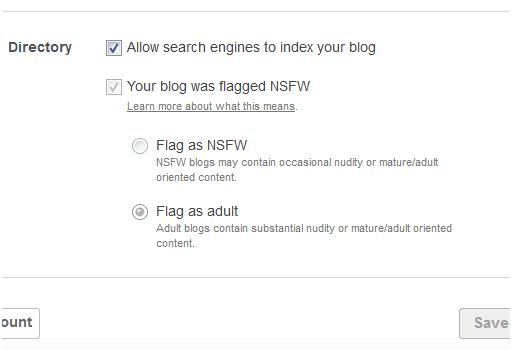
That checkbox is a lie. It’s nicely checked, it’s not greyed out, but if your blog is flagged “adult” it’s a lie. Do you see the “Learn more about what this means” link under “Your blog was flagged NSFW” selector? It leads to this page, where Tumblr requests users to appropriately self-flag their blogs:
Please respect the choices of people in our community and flag your blog as NSFW or Adult from your blog Settings page.
- NSFW blogs contain occasional nudity or mature/adult-oriented content.
- Adult blogs contain substantial nudity or mature/adult-oriented content.
If you’re not sure if you should flag your blog you can leave it unflagged, but keep in mind that we might flag it later if we see a lot of mature/adult-oriented content.
To answer the question “What happens to blogs that are flagged NSFW or Adult?” Tumblr offers this handy chart. The key piece of information is the white space indicated by my red superimposed arrow:

That’s right — where the “Blog indexed by Google” row intersects the “Adult Blogs” column, we find a ringing silence.
Would you have noticed? None of the adult Tumblr bloggers I know ever did. I knew from my porn researching that adult Tumblrs tended to be poorly represented in Google search results, but I chalked it up to the sheer scale of Tumblr and Google’s growing bias against returning porn search results. Nope, I found out the truth in one stark moment of astonishment, summed up by this image:
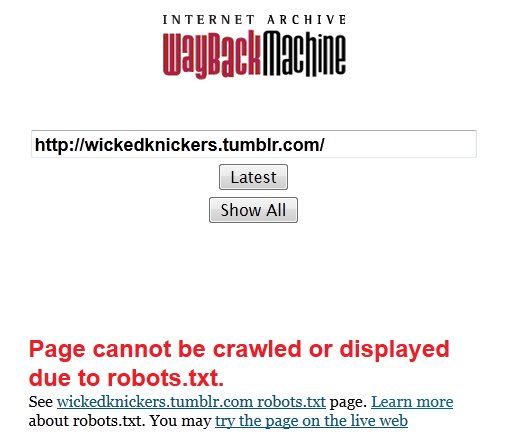
Let’s click the “See wickedknickers.tumblr.com robots.txt page” link:
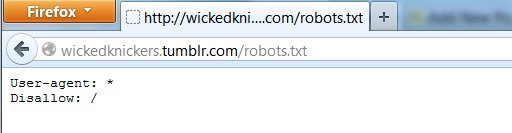
From me: Aghast. Fucking. Gulp.
In robot, that means, roughly “All robots: stay out!” No search spiders allowed. No Internet Archive crawler. The Wicked Knickers tumblr is there, but you have to know about it, or you have to be linked to it. You won’t find it in Google, you won’t find it in any other search engine that honors robots.txt, and when Tumblr decides to stop hosting it, you won’t find the pages in the Wayback Machine — it will be gone for good, lost to humanity unless somebody with the technical chops and outlaw sensibilities of Archive Team finds a way to archive it anyway, robots.txt be damned.
Wicked Knickers is just an example, one that has some meaning to me because it’s one of the first Tumblr blogs I ever noticed, and I’ve been linking to it since 2010. That’s almost 6,000 vintage erotica posts since January 2009, and none of those pages are in Google or the Wayback Machine. It was only when I twigged to that anomaly that I finally understood what Tumblr is doing to adult blogs.
In all the years that I’ve been preaching Bacchus’s First Rule (“Anything worth doing on the internet is worth doing on your own domain that you control”), I’ll confess that I never considered the power of robots.txt, or what it means to be putting stuff on an internet site where somebody else controls what robots.txt says. Not only do they control your visibility to search engines, they control whether history will remember what you said. That strikes me as a high price to pay for a “free” blogging platform.
It’s worth noting that there’s still rather a lot we don’t know about the Tumblr robots.txt blockade on adult Tumblr sites. Unanswered questions include:
- Does Tumblr have any flexibility on this? Would their support, if asked, remove or modify the robots.txt barrier in specific cases?
- When did Tumblr start using robots.txt to block Google from adult blogs? Has it always been like this, or is it a recent innovation?
- Why does Tumblr display the misleading checkbox that falsely implies that search engines can see flagged adult blogs?
- What is the actual reason for excluding adult Tumblrs from search engine and (especially) archive crawls?
In an unusual move for me, I actually reached out to press@tumblr.com, told Tumblr I was going to write this post, and asked them for answers to those questions. That was on May 11th. No response so far. If they ever do answer, I’ll be sure to update this post.
Similar Sex Blogging:
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
|
|